Using just parcel data shapes to estimate segments of road that are >45' feet wide. pic.twitter.com/SIvbCf0nIw
— Kuan Butts (@buttsmeister) February 16, 2018
Above: The tweet that was the basis for this blog post.
Introduction
Senate Bill 827 proposes upzoning within one quarter and one half mile of high quality transit stops. Identifying those zones is a task that has already been approached. Two examples include Transit Rich Housing, which identifies all upzoned areas in California, and my previous post on identifying issues with what constitutes a high quality bus stop.
Using either of these, resources, we can identify high quality stop locations. With these stops in hand, we have an additional hurdle. While we know that all sites are being upzoned, the proposition is that those facing streets wider than 45’ be up zoned more so.
The proposition currently states 45’ curb to curb but, as this San Francisco Planning Department memo points out, street width is more often measured via the right of way available. Regardless of how this is measured, it is this aspect of the bill that is most difficultly to measure. This is due to the fact that there is limited data available on street widths.
Post Structure and Logic
This post will propose a method of identification of street width that uses only parcel data. The reason for using only parcel data is that this is the most common and most consistent data available for major urban metros in California. While there is good road segment data for most of the major urban areas of the state available on OpenStreetMap, it is lacking in sufficient accuracy of street width.
Due to this, I want to explore a method that relied on the least amount of data possible. In this post, I will describe a method of identifying street width that relies solely on the geometries of the parcels that are within a quarter mile of each qualifying bus stop. Also, we will use the valid stops dataset that was generated from the workflow presented in my last blog post as a reference layer to find the bus stop locations that are to be evaluated.
Getting started
Here are the libraries we will be using to execute this post’s workflow:
import geopandas as gpd
import pandas as pd
from shapely.geometry import shape, MultiPoint, Point, Polygon, MultiPolygon, boxGenerating base data
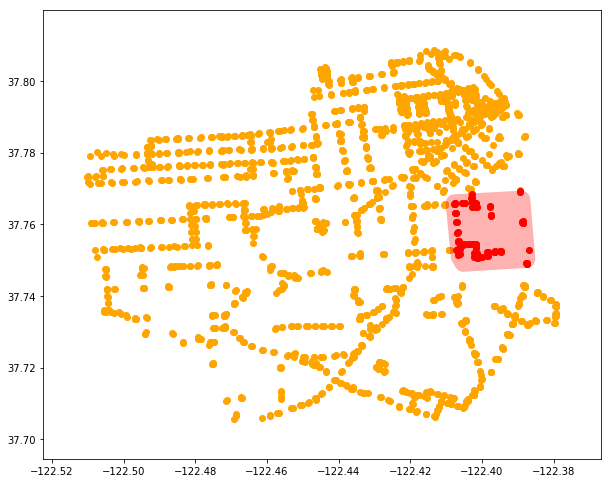
As described earlier, the base stops points are based on the data used in this example project.
For the purposes of this post, we will work on just a subset of all these stops. The operation described is not terribly performant, so processing all stops in the state would be a task best performed with parallelization.
I’ve subset the stops to the area in the bounds, which I drew as a GeoJSON at geojson.io.
all_stops_sub = all_stops[all_stops.intersects(bounds)]For parcels data, I’ll use the parcels dataset available from DataSF, San Francisco’s open data portal.
Both the stops and the parcels are then loaded up into GeoDataFrames and cast in 2163 equal area meter projection:
# Read in SF parcels shape file downloaded from DataSF
# Note: Sorry about using Shapefile format :)
gdf = gpd.read_file('sf_parcels/')
gdf_clean = gdf[~gdf.geometry.isnull()]
# Reproject from initial, 4326 EPSG
gdf_clean = gdf_clean.to_crs(epsg=2163)Creating target base layers
Now that we have our data represented as Python objects, we should be able to trip each down to just what we care about. In the case of the parcel data, we only care about the geometric shapes. As a result, we can pair the data down to just a GeoSeries:
gs_blocks = gpd.GeoSeries([g for g in gdf_clean.geometry])
gs_blocks = gs_blocks.reset_index(drop=True)Then, we can convert the bus stops in the target area to a series of Shapely Point objects:
gcp = gpd.GeoDataFrame(geometry=[Point(stop) for stop in all_stops_sub])
gcp.crs = {'init': 'epsg:4326'}
gcp = gcp.to_crs(epsg=2163)Once that is done, we can also buffer the resulting GeoDataFrame and union the new point shapes:
# Buffer by 1/4 mile
gcp = gcp.buffer(402)
target_nodes = gcp.unary_unionThis gives us the 1/4 mile coverage area from each bus stop that we are to be examining. All these parcels qualify under SB827 to be upzoned.
What needs to be identified is which of these are along a street greater than 45’? We will attempt to estimate this by performing a series of geometric operations on the parcel shapes against all of their neighbors to assess which parcels are on streets that are likely greater than 45’.
To do this, let’s first subset all the parcel shapes to just those that intersect with these 1/4-mile buffer areas:
# Let's get all blocks that are within a some radius of the target node
gs_blocks_sub = gs_blocks[gs_blocks.intersects(target_nodes)]
gs_blocks_sub = gs_blocks_sub.reset_index(drop=True)Here, we can see the resulting subset:
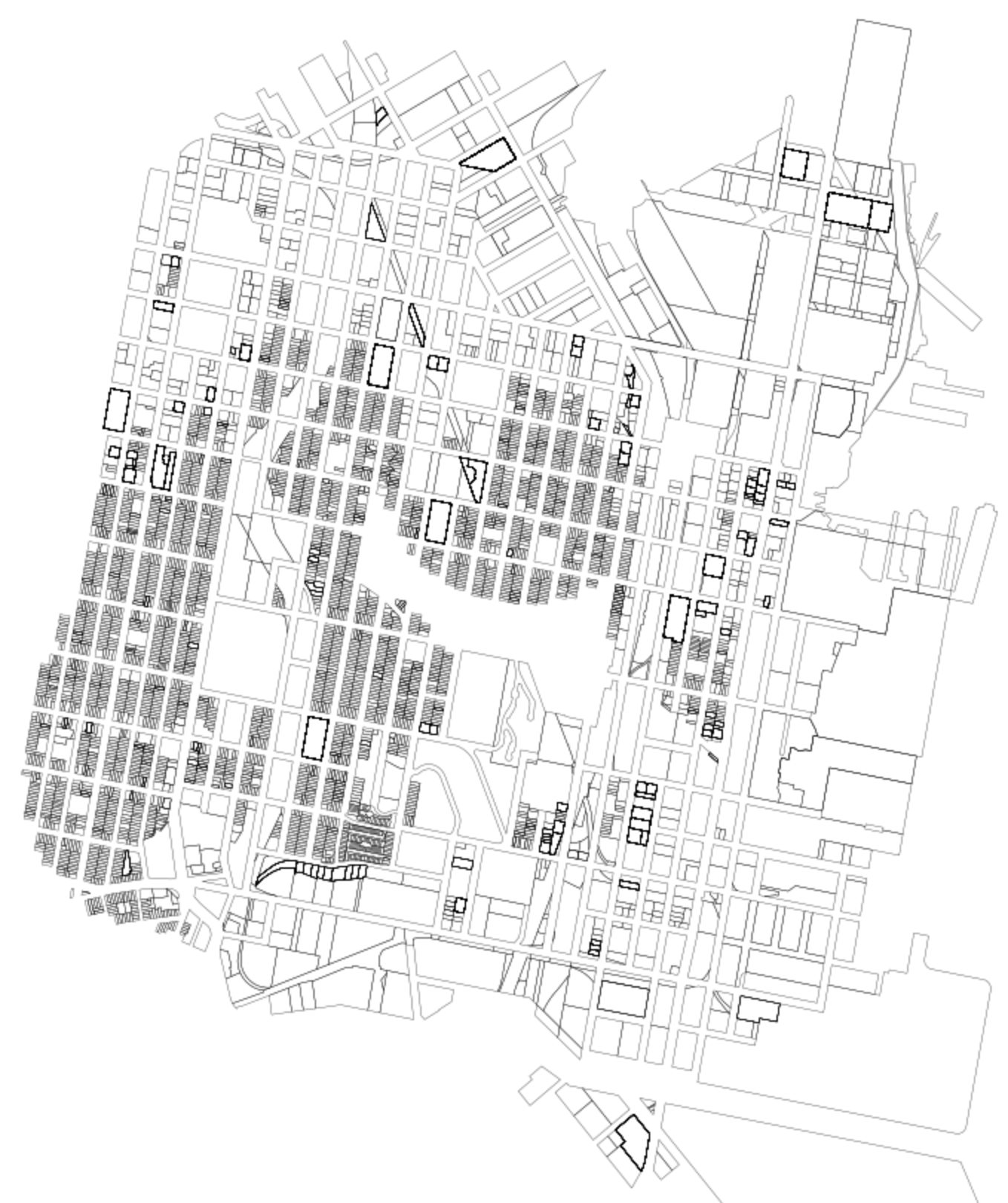
Similarly, let’s generate the same data, but for areas at a 45-foot and 200-foot buffer around each parcel:
gs_block_buffered_45 = gs_blocks_sub.buffer(feet_to_meter(45))
gs_block_buffered_45 = gpd.GeoSeries([g.simplify(5) for g in gs_block_buffered_45])
gs_block_buffered_200 = gs_blocks_sub.buffer(feet_to_meter(200))
gs_block_buffered_200 = gpd.GeoSeries([g.simplify(5) for g in gs_block_buffered_200])Because we will be performing a number of spatial intersections on these GeoDataFrames as a whole, it is worthwhile to produce spatial indices for each:
# Make spatial indices for all
gs_blocks_sub_sindex = gs_blocks_sub.sindex
gs_block_buffered_45_sindex = gs_block_buffered_45.sindex
gs_block_buffered_200_sindex = gs_block_buffered_200.sindexThese will be used in conjunction with the following function:
def indexed_intersection(spatial_index, polygon, gdf):
possible_matches_index = list(spatial_index.intersection(polygon.bounds))
possible_matches = gdf.iloc[possible_matches_index]
precise_matches = possible_matches[possible_matches.intersects(polygon)]
return precise_matchesThis allows us to perform the intersections while leveraging Rtree which will enable faster intersections on these larger parcel datasets. Note: Thanks to Twitter user @sidkap_ for reminding me to use spatial indexes here.
At this point, we are ready to enter the main analysis logic.
Core algorithm introduction
At this point, we will iterate through each of the geometries in the parcels subset GeoDataFrame.
# All together in one big sloppy loop
all_uus = []
for i in range(len(gs_blocks_sub)):
block_orig = gs_blocks_sub.geometry.values[i]
…Note that this isn’t going to be the most elegant method, but will be sufficient for outlining how such a system would work. Further refinements should be made to improve this in the name of both efficiency and legibility.
Core algorithm
What will be described below will be performed once for each for loop cycle.
First, we find all parcels that are closer than the 45’ distance. We assume the space between these parcels is either none or a street less than 45’ away. We use the pre-buffered 45’ dataset Against the target parcel to find all other parcels that fall within this definition.
# First find all the buildings closer than 45 feet
buffered_block_45 = gs_block_buffered_45.geometry.values[i]
blocks_too_close = indexed_intersection(gs_block_buffered_45_sindex, buffered_block_45, gs_blocks_sub)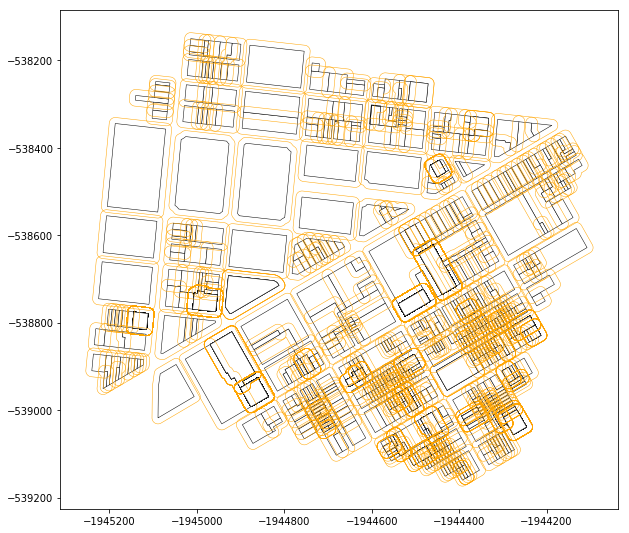
We do the same with the 200’ buffered dataset. 200’ is an arbitrary value. I use it as a distance that I assume most street widths will not exceed and thus, as a result, I feel safe omitting all parcels that fall outside of that distance when trying to find street area.
# Now pull all "potential" buildings in as well (I'd define these
# all buildings within 150 feet or so)
buffered_block_200 = gs_block_buffered_200.geometry.values[i]
all_nearby = indexed_intersection(gs_block_buffered_200_sindex, buffered_block_200, gs_blocks_sub)Note: Prior to the update to include spatial indexing, the above 2 intersection operations looked like this:
# Now pull all "potential" buildings in as well (I'd define these
# all buildings within 150 feet or so)
buffered_block_200 = gs_block_buffered_200.geometry.values[i]
mask_200 = gs_blocks_sub.intersects(box(*buffered_block_200.bounds))
all_nearby = gs_blocks_sub[mask_200]Now what I want is just the parcels that are within 200’ of the target parcel but also not within 45’ of the target parcel:
# And drop any that were caught by the first buffer
same_as_within_45 = all_nearby.index.isin(blocks_too_close.index)
all_nearby = all_nearby[~same_as_within_45]From this point on, we need to iterate through all_nearby and find just the parcels that are “across” from the target parcel. To do this we perform the following looped operation:
intersecting_areas = []
for ani in range(len(all_nearby)):
# Get the minimum distance from that geometry to the target one
nearby_geom = all_nearby.geometry.values[ani]
meter_dist = nearby_geom.distance(block_orig)
# Sanity check: Just bail if the distance is too great
if meter_dist > 200:
continue
# Now buffer the target block by that distance
block_orig_buff = block_orig.buffer(meter_dist)
# And then find the intersection size of a 1 meter buffer
# of the nearby geometry
intersection = block_orig_buff.intersection(nearby_geom.buffer(1))
# If there is some amount of remaining space there
# that is more than just a corner's worth (something
# that would be on an opposite corner and not actually
# across the street, relies on parcels not having jutting shapes)
if intersection.area > 1.5:
nearby_buff = nearby_geom.buffer(meter_dist)
int_area = block_orig_buff.intersection(nearby_buff)
intersecting_areas.append(int_area)I’ll break this down here.
For each nearby parcel, we first get the distance it is away from the target parcel:
# Get the minimum distance from that geometry to the target one
nearby_geom = all_nearby.geometry.values[ani]
meter_dist = nearby_geom.distance(block_orig)There’s a redundant sanity check to just toss any definite outliers:
# Sanity check: Just bail if the distance is too great
if meter_dist > 200:
continueThen we buffer the target parcel to the edge of the other nearby parcel:
# Now buffer the target block by that distance
block_orig_buff = block_orig.buffer(meter_dist)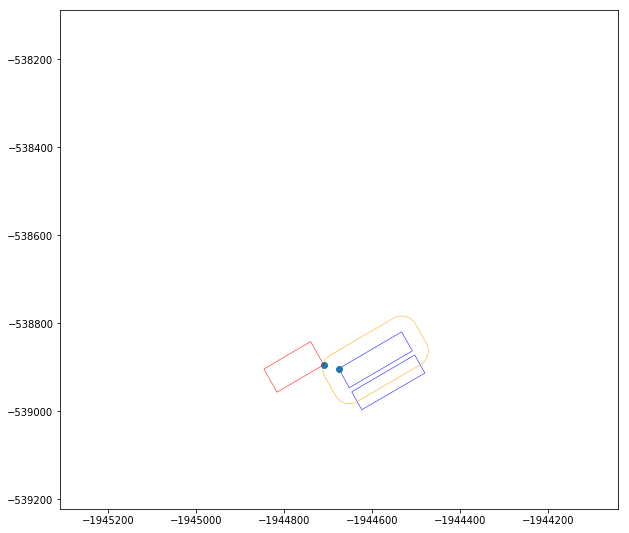
Note: The above image an example showing the operation that is being performed. The site used in this example is a different location that the Dogpatch subset. This is for explanatory purposes only.
Then I do something janky: I buffer the other parcel by 1 meter and check what the intersection size is.
# And then find the intersection size of a 1 meter buffer
# of the nearby geometry
intersection = block_orig_buff.intersection(nearby_geom.buffer(1))If the size of the intersection area is small, I can assume we have a situation where the parcel is diagonal to the target parcel. Thus, only a corner is intersecting. These parcels will be ignored.
If the nearby parcel passes this sniff test, I buffer both it and the target parcel the same distance (the distance each is away from the other). I then intersect these two buffers and send that shape up to the intersecting areas tracking list:
if intersection.area > 1.5:
nearby_buff = nearby_geom.buffer(meter_dist)
int_area = block_orig_buff.intersection(nearby_buff)
intersecting_areas.append(int_area)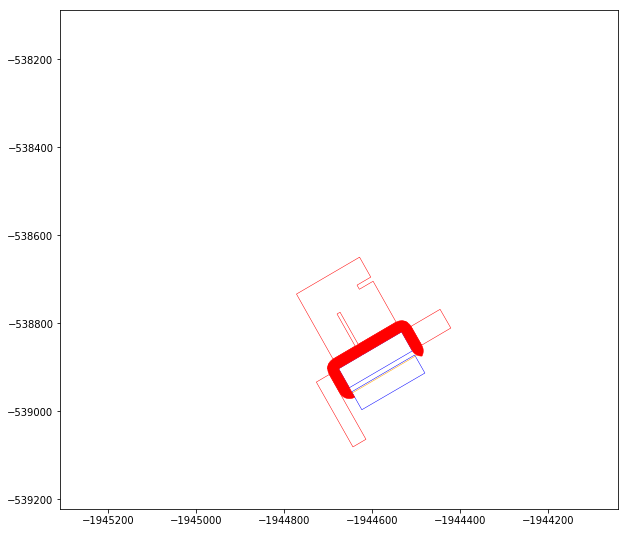
Note: The above image an example showing the operation that is being performed. The site used in this example is a different location that the Dogpatch subset. This is for explanatory purposes only.
Once the loop is done, I can union all the intersection areas and create a single geometry for that parcels adjoining street shapes:
uu = gpd.GeoSeries(intersecting_areas).unary_union
all_uus.append(uu)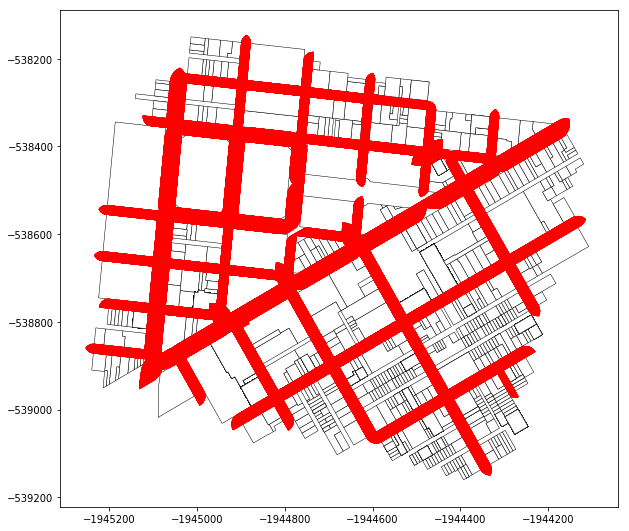
Note: The above image an example showing the operation that is being performed. The site used in this example is a different location that the Dogpatch subset. This is for explanatory purposes only.
Processing intersection shapes of nearby streets
Once each parcel has been processed, we have a list of nearby street shapes for each parcel. These need to be joined together and then the shape of the parcel footprints punched back out of the shapes (to trim them up):
# Generate the boundary of the buffer area that is diffed out
# from the parcel shapes
print(f'processing {len(all_uus)} all_uus')
all_uus_uud = gpd.GeoSeries(all_uus).unary_union
gss_uud = gs_blocks_sub.unary_union
boundary = gs_blocks_sub.unary_union.convex_hull.buffer(feet_to_meter(45) * (-2))
uus_diffed = gpd.GeoSeries(all_uus_uud).difference(gss_uud)
uus_diffed = uus_diffed.intersection(boundary).unary_union
uus_diffed = gpd.GeoSeries([g for g in uus_diffed if isinstance(g, Polygon)]).unary_unionFinal results
Once we have generated the final variation of the uus_diffed variable, we simply need to identify which parcels touch this shape representing large streets. Those parcels that do abut this geometry are parcels that get the additional wide street bonus (highlighted in green). Those that do not abut this shape do not receive that additional height increase.
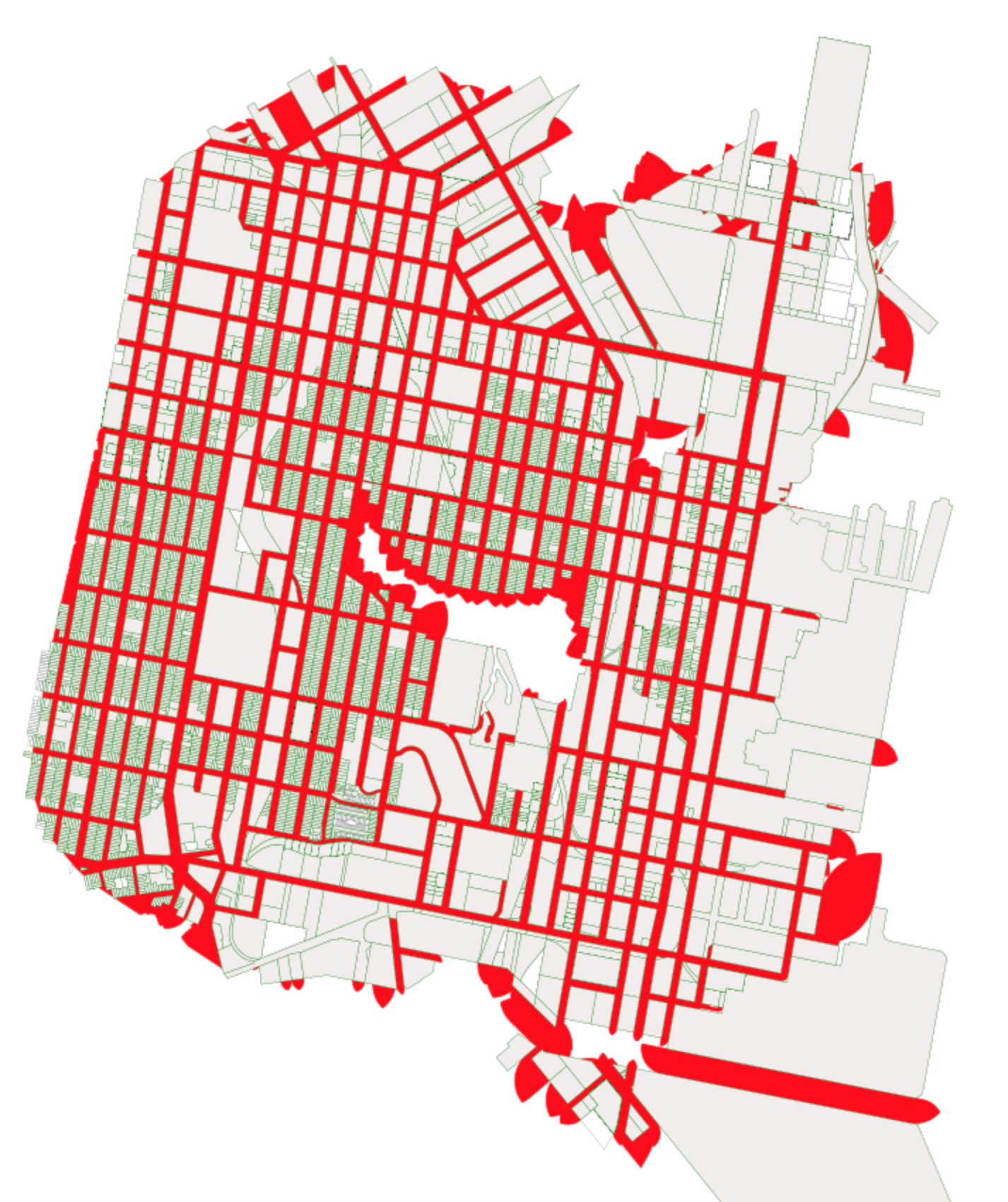
As you can see in the resulting image, most of San Francisco is likely to be upzoned at the wide street height, due to the size of its roads. This is an observation that was echoed in the SF Planning Department’s memo from last week.
A note on the addition of spatial indexing
Thanks to Twitter user @sidkap_ for reminding me to use spatial indexing to speed up the intersection checks. Originally the Dogpatch operation shown above took about 35 minutes to complete. With the implementation of spatial indexing, the runtime was improved, to under 15 minutes.